No One Knows Your Data Better than You (Even in Oracle 18c)
Oracle’s cost based optimizer is an amazingly sophisticated piece of software, but still it manages to confuse us by how it handles some queries. The reason is that usually we still know more about our data than the optimizer does. But with 18c you get the possibility to leverage these effects with the help of the pluggable optimizer which already is my favourite 18c feature. It will be available in 18.1.4.
So how does it work? You might have read about the Oracle Database Multilingual Engine (MLE). The actual reason MLE was introduced was to enable developers to write their own pluggable optimizer cartridges (POC).
Now you can - depending on your personal preferences - create optimizers in your favourite language and customise them depending on your application’s specific requirements. Sounds cool, doesn’t it?
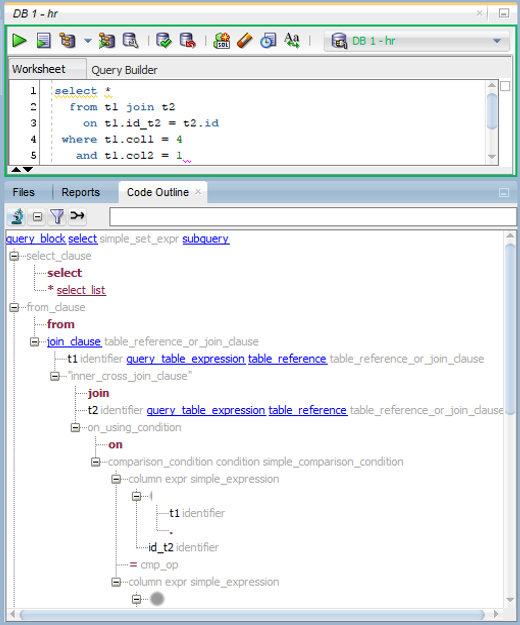
SQL Statement Parse Tree
The basis you can build your optimizer cartridge on is the statement’s parse tree. You can access existing statistics and histograms, gather statistics on the fly, and combine them with different transformations. The standard transformations like join elimination, view merging, subquery unnesting, join predicate pushdown, and join factorization are available via API, so you don’t have to reinvent the wheel. In case of failure the database falls back to the standard cost-based optimizer, so the application doesn’t need to handle an exception. The information about which optimizer has been used can be found in the trace file. Within PL/SQL you can access it after every SQL or DML statement with SQL%OPTIMIZER which returns a string.
This is a standard explain plan:
---------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows |
---------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |
|* 2 | HASH JOIN | | 1 | 819K| 900K|
|* 3 | TABLE ACCESS FULL| T1 | 1 | 819K| 900K|
| 4 | TABLE ACCESS FULL| T2 | 1 | 1000K| 1000K|
---------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."ID_T2"="T2"."ID")
3 - filter(("T1"."COL1"=4 AND "T1"."COL2"=1))
And this is the plan our pluggable optimizer generated:
Plan optimizer name: OPT_FIRST_V04
---------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |
| 2 | NESTED LOOPS | | 1 | | 10 |
| 3 | NESTED LOOPS | | 1 | 1 | 10 |
|* 4 | TABLE ACCESS FULL | T1 | 1 | 1 | 10 |
|* 5 | INDEX UNIQUE SCAN | T2_IDX | 10 | 1 | 10 |
| 6 | TABLE ACCESS BY INDEX ROWID| T2 | 10 | 1 | 10 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter(("T1"."COL1"=4 AND "T1"."COL2"=1))
5 - access("T1"."ID_T2"="T2"."ID")
As you need special grants to plug your optimizer cartridge (define optimizer and execute optimizer) we can’t test it on LiveSQL (yet?) but as soon as 18c will be available for download we can start coding and testing. If you want to view examples and share your best optimizer cartridges, go to Optimizer Cartridge Exchange. Looking forward to your ideas!